本篇文章翻譯自Timeslicing Batched Algorithms in Games,原作者為CJ Cat。
這篇是我遊戲程式系列的文章之一。
用來產生文章中動畫的原始碼在GitHub上可以找到。
時域切割(timeslicing)是改善批次演算法(batched algorithms,多個相同演算法的實體)時相當有用的技巧。將多個演算法的實體分散到多個影格(frame),而非在一個影格中執行所有實體的演算法。
舉個例子,如果你在遊戲關卡中有100個NPC,一般來說你不用每個影格都計算出每個NPC的決策;只讓50個NPC做出決策可以降低50%決策方面的效能消耗,25個NPC則降低75%,20個NPC則降低80%。
注意我說的是切割決策,不是切割整個NPC的更新流程。在每一個影格中,我們還是希望NPC依照最新的決策來移動,或至少移動離玩家最近、最容易被注意到的那些。額外的動畫層通常可以蓋過那些因為時域切割而造成的微小延遲。
另外要注意的是,我將不會討論如何在多個影格中完成單一個演算法,那也是時域切割的一種形式,但不在這篇文章所討論的範圍。這篇文章會把焦點放在將多個相同演算法的實體,分散在多個影格中計算,而每個實體都小到足以在一個影格中完成。
這種時域切割的技巧並不適用於對延遲極度敏感的情形。如果只是一個影格的延遲都會對你的演算法造成嚴重影響,那把它們切割可能不是一個好主意。
這篇文章中我將會提到:
- 批次執行多個簡單演算法實體的範例。
- 如何對這樣的批次演算法做時域切割。
- 根據輸入及輸出的時機,對時域切割作分類。
- 時域切割公用類別(class)的範例實作。
- 最後,如何跟執行緒搭配使用。
範例
我使用的範例是一個簡單的邏輯——讓NPC面向單一個目標。每個NPC的決策層會計算面對目標所需的方向,然後動畫層會試著在旋轉速度有上限的情形下,將NPC旋轉至他們想要的方向。
首先,先看看如果每個NPC在每個影格中都執行這個演算法(更新全部,Update All),看起來的動畫是怎麼樣的。
移動的圓圈是目標,黑色的箭頭是NPC以及他們現在面對的方向,然後紅色的箭頭代表每個NPC想面對的方向。
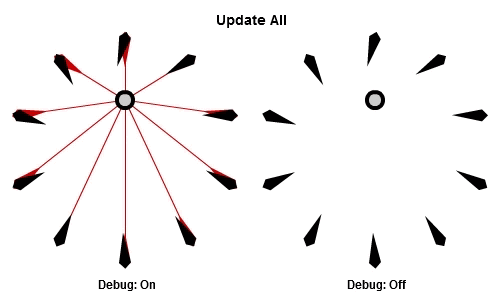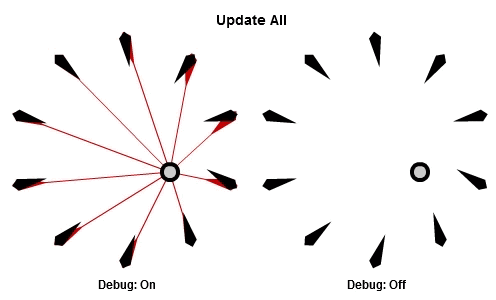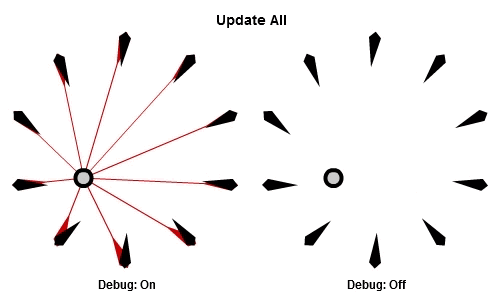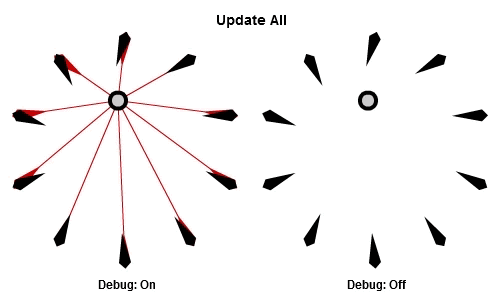
這個程式看起來大概像這樣:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| void NpcManager::UpdateFrame(float dt) { for (Npc &npc : m_npcs) { npc.UpdateDesiredOrientation(target); npc.Animate(dt); } } void Npc::UpdateDesiredOrientation(const Object &target) { m_desiredOrientation = LookAt(target); } void Npc::Animate(float dt) { Rotation delta = Diff(m_desiredOrientation, m_currentOrientation); delta = Limit(delta, m_maxAngularSpeed); m_currentOrientation = Apply(m_currentOrientation, delta); }
|
就像剛才提到的,一般來說你不用每個影格都更新NPC的決策。我們可以用這樣達到初步的時域切割效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| void NpcManager::UpdateFrame(float dt) { const unsigned kMaxUpdates = 4; unsigned npcUpdate = 0; while (npcUpdated < m_numNpcs && npcUpdated < kMaxUpdates) { m_aNpc[m_iNpcWalker].UpdateDesiredOrientation(target); m_iNpcWalker = (m_iNpcWalker + 1) % m_numNpc; ++npcUpdated; } for (Npc &npc : m_npcs) { npc.Animate(dt); } }
|
有時候這種直接的方法就已經足夠,但有時你需要對輸入及輸出的時機做更多控制。下面有更深入使用時域切割的邏輯,可以讓你根據特定需求選擇不同的輸入輸出時機。
在繼續之前,先看看這篇文章中所使用的術語。
術語
- 完成一批(a batch)的意思是,每個NPC的決策邏輯都完整執行一次。
- 一件工作(job)代表執行一個NPC的決策邏輯的動作。
- 輸入(input)是執行一件工作所需的資料。
- 輸出(output)是完成一件工作後得到的結果。
接下來是時域切割的邏輯。
時域切割
這裡的流程是切割批次演算法的一種方法。在效率及記憶體使用上可能不是最佳的,不過我認為這種方法在邏輯上很清楚,也很容易維護(也代表適合用於展示)。所以除非對於微小的優化有絕對需求,否則我不會太擔心這個問題。
- 開始新的一批。
- 找出所有需要完成的工作。為每一件工作編上獨特的鍵值(key),這個鍵值可以推斷出該件工作所需的輸入。
- 為每件工作準備一個工作參數的實體,它是鍵值、輸入和輸出的集合。
- 開始執行,直到該影格內完成的工作數量到達上限
- 依照輸出的時機(詳細後述),將工作的結果,包含了該工作的輸出以及對應的鍵值,存入一個環形緩衝區(ring buffer)。這個緩衝區代表了工作結果的履歷。後面的遊戲邏輯會利用鍵值來查詢最新的結果。
- 當所有工作都完成後,這一批就算結束了。然後重覆整個過程。
用key值來查詢輸出的一個好處是,即使不同的時域切割系統互相參考了對方的輸出,它們依然可以共同運作得很好。就系統上來說,一個系統利用鍵值來查詢輸出,而另一個系統回應一個與該鍵值相應的最新輸出。有點像是一個迷你資料庫。
在我們的範例中,因為每一件工作都跟一位NPC相關聯,用NPC作為工作的key值看起來滿適合的。
接下來,以讀取輸入和儲存輸出的時機來分類,時域切割有這幾種類型:
注意:這裡使用的字眼「同步」和「非同步」跟多執行緒無關。這裡的用字只是為了區別操作的時機。在後面的「執行緒」章節之前,所有出現在這篇文章的東西都是單執行緒的。
- 非同步輸入:輸入的資料會在某一件工作要開始時被讀取
- 同步輸入:每一件工作的輸入資料都會在一批工作要開始時被讀取
- 非同步輸出:一件工作的輸出,在該件工作結束時就馬上儲存
- 同步輸出:所有的輸出在一批工作完成後才一起儲存
我們使用ring buffer,所以後面的遊戲邏輯可以對時間一無所知,把輸出(用key查詢到的)認為是最新的。
把不同的輸入輸出時機作組合,會得到四種組合。非同步輸入/非同步輸出(AIAO)、同步輸入/同步輸出(SISO)、同步輸入/非同步輸出(SIAO)、以及非同步輸入/同步輸出(AISO)。我們會一個一個來談。
出於示範的目的,下面所有動畫反映的是,設定成一個frame只會有一件工作開始的狀況。在真實的遊戲中,如果出現了不可接受的延遲的話,這個數字應該要設的更高。
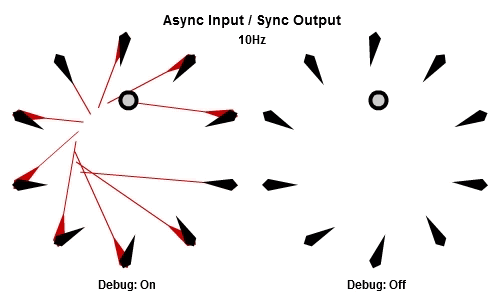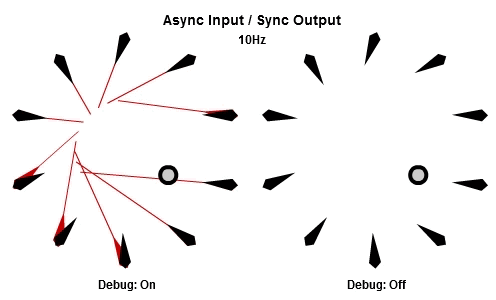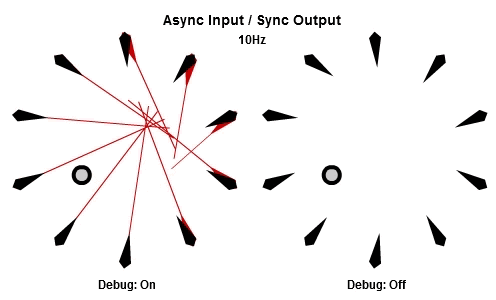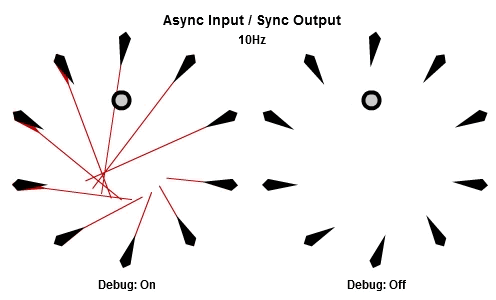
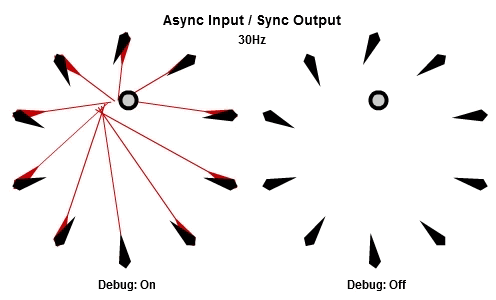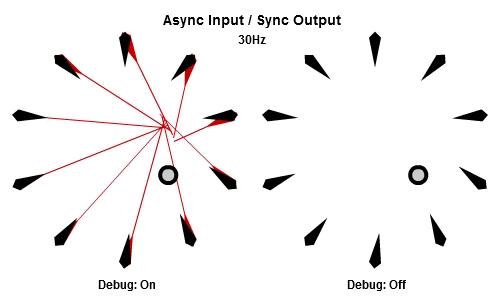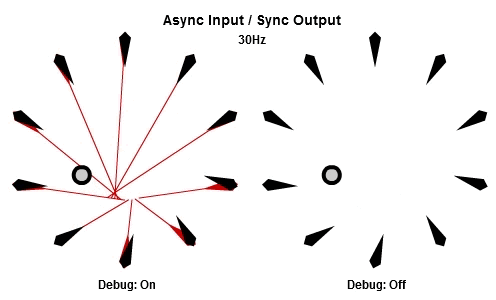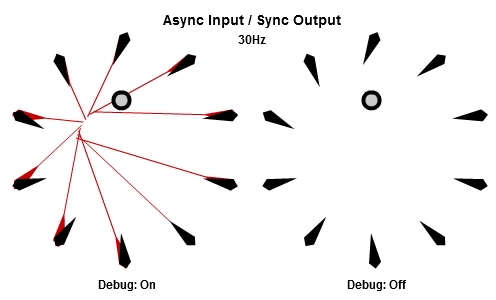
非同步輸入/非同步輸出
對於將NPC轉向目標的這個例子來說,AIAO的組合可能是最合理的。輸入在一件工作開始的時候被讀取,所以那一件工作會有目標最新的位置。輸出在工作完成立刻儲存,其中包含了NPC想要面對的方向,所以NPC的動畫層可以立刻對最新的目標方向做出反應。
這個動畫展示了如果我們用10Hz的頻率執行工作(1秒執行10個NPC的工作),看起來是什麼樣子。
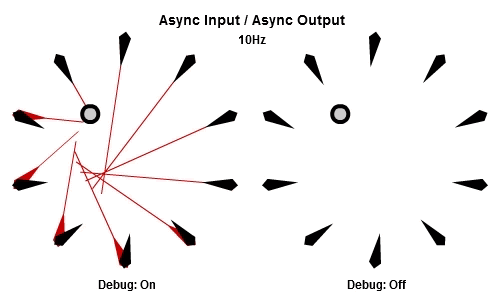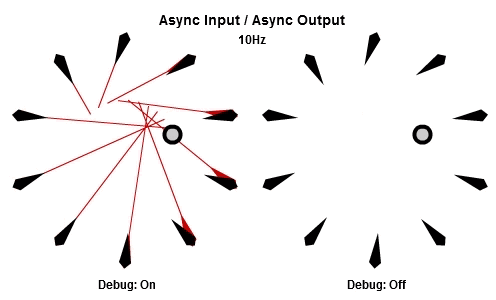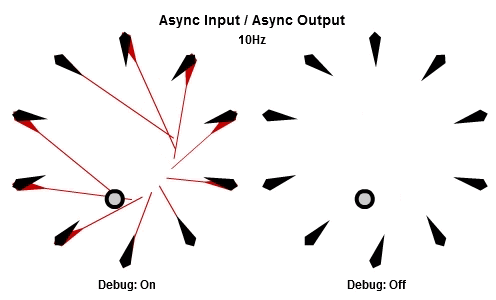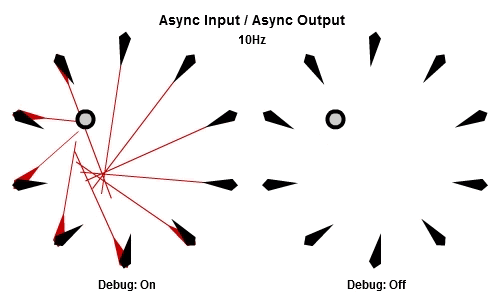
然後這個是30Hz看起來的樣子。
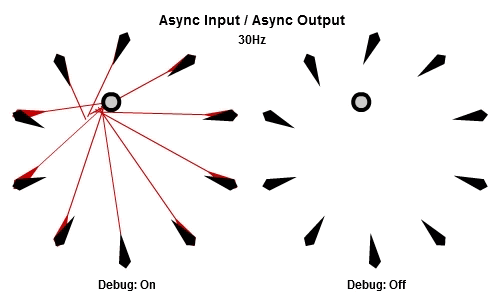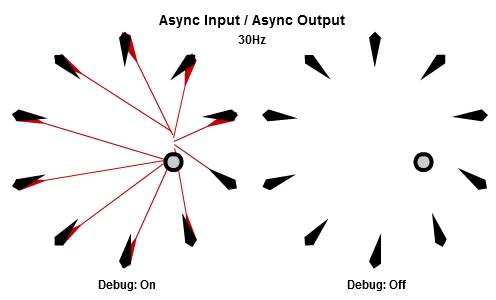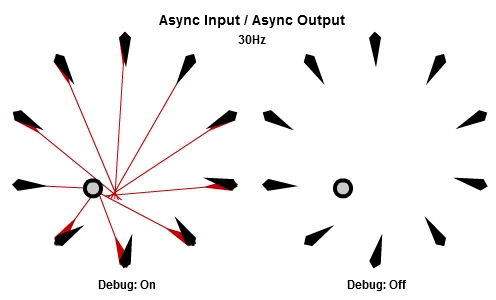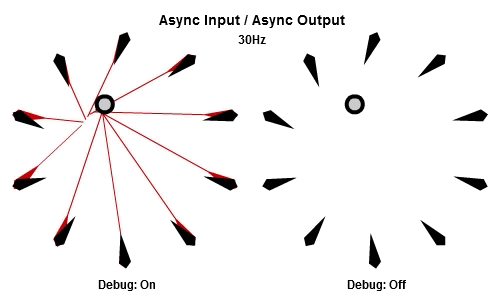
你可以看到每個NPC一直等到工作開始才取得目標的最新位置,然後在工作結束後立刻更新他想要的方向。
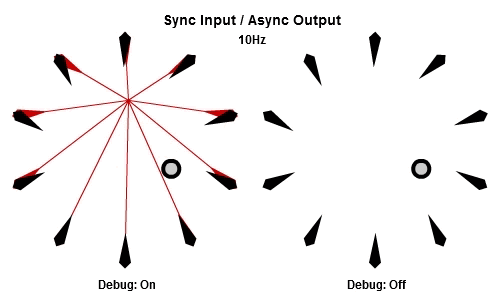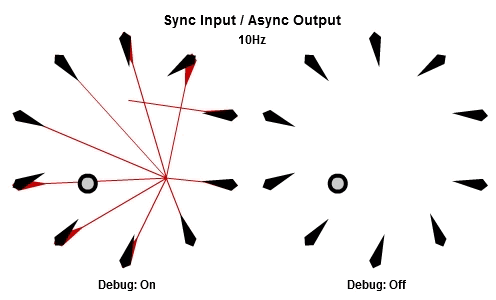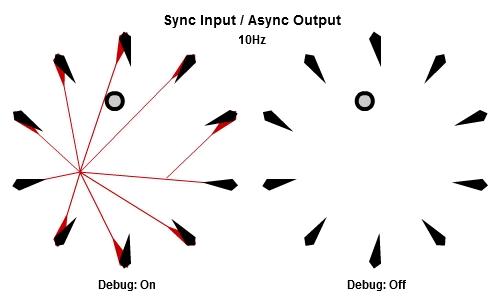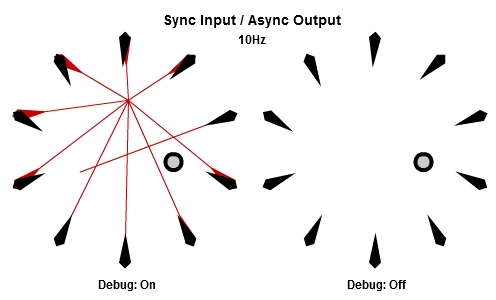
同步輸入/非同步輸出
上面展示的AIAO組合的狀況,當中的非同步輸入會造成無謂的搖晃,不過我們還是想要NPC在工作結束後立刻做出反應,那我們可以使用SIAO組合。
這個是10Hz的版本。
然後這個是30Hz的版本。
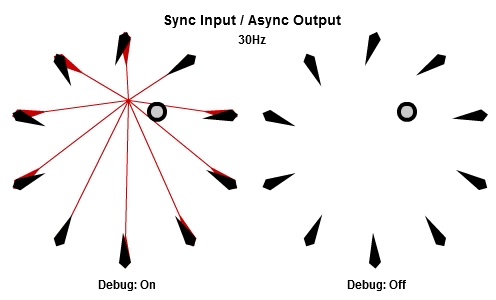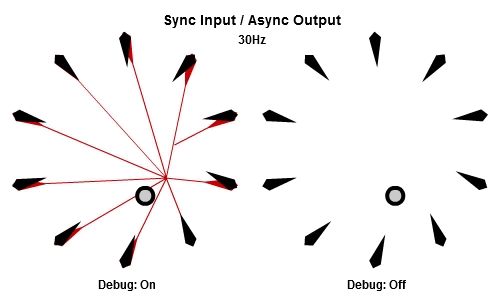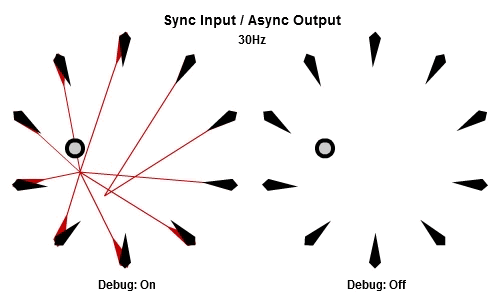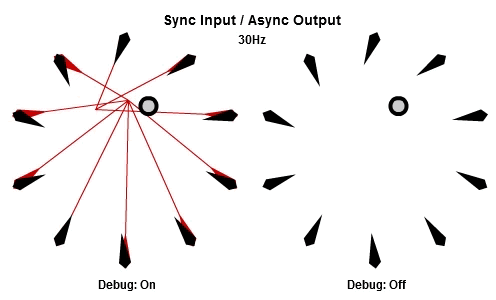
注意到當每個工作開始時,他們使用相同的目標位置作為輸入,這個位置已經在這一批開始時被同步了,而為了NPC能夠立刻做出反應,輸出在工作結束時就立刻儲存。
這個實際上與之前提到的時域切割的初步做法一樣。
同步輸入/同步輸出
解釋SISO組合最好的方法可能是先看動畫。下面的動畫依序是10Hz與30Hz的版本。
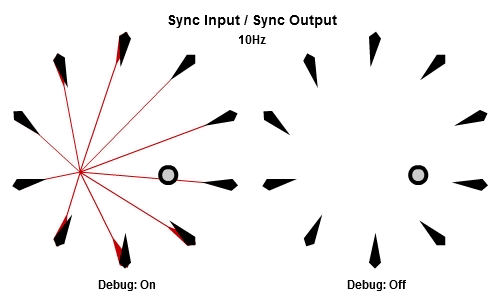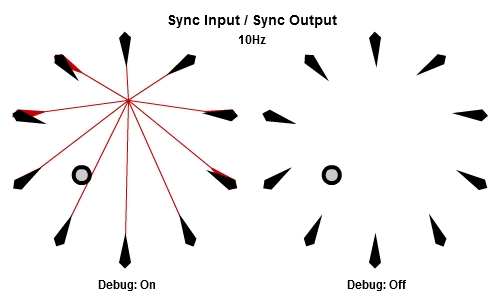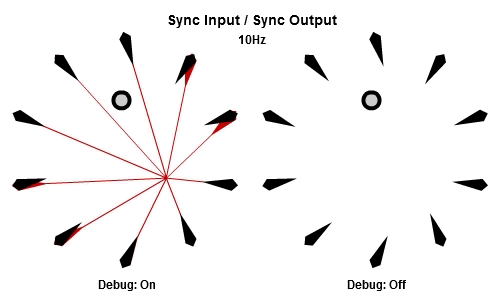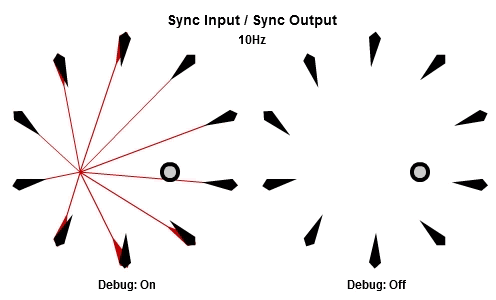
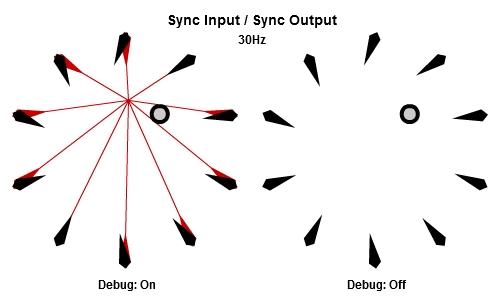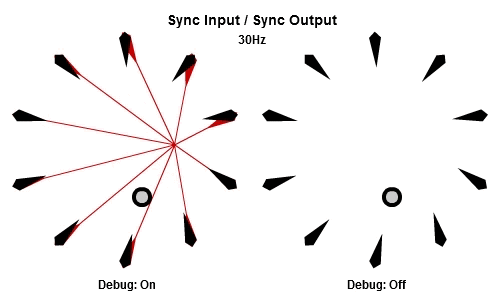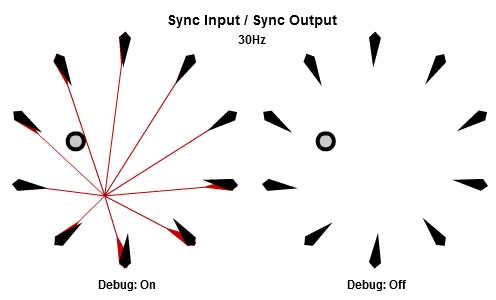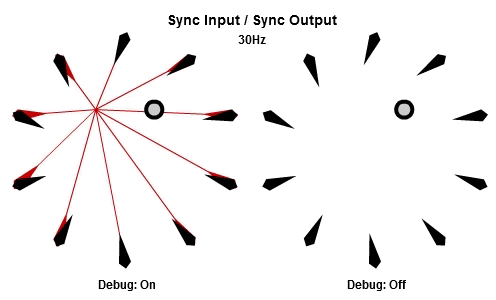
一開始的做法是每個frame都更新全部NPC,這個做法基本上是它的「延遲」版。所有工作的輸入在那一批開始的時候同步,並且所有的輸出在那一批結束的時候被儲存。本質上這是一種「雙緩衝」,最新的結果一直到該批內所有工作都完成後才反映。因為這個原因,要讓同步輸出的組合能夠正常運作,作為履歷的ring buffer必須要有一批次最大工作數量的至少兩倍大。
對於我們這次的範例,SISO組合大概不是理想的選擇。不過,對於一些狀況例如更新influence maps、heat maps、或是任何有關遊戲空間的分析,SISO組合可以証明是有用的。
非同步輸入/同步輸出
老實說,我沒辦法想出一個情境是適合使用AISO組合的。它被包含在這裡只是出於完整性的考量。請看下面的動畫,依序是10Hz與30Hz的版本。如果你可以想到一個例子是使用AISO組合會比其他三種更好的,請在留言分享你的想法或是寄e-mail給我。我真的很想知道。
範例實作
現在我們已經看過四種時域切割的組合,是時候來看一個範例實作了,這個實作會正確的做到我們前面所談的東西。
在直接切入時域切割的核心邏輯之前,先來看看它是怎麼插入我們之前看到的NPC程式碼中。
timeslicer公用類別允許使用者提供三個函式。一個為新的批次設置key(把key寫入一個陣列並回傳新批次的大小),一個為工作設定它的輸入(依照該工作的key將輸入的資料寫到input),還有一個函式是要被切割的程式邏輯(依照key以及輸入的資料寫到output)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
| class NpcManager { private: struct NpcJobInput { Point m_targetPos; }; struct NpcJobOutput { Orientation m_desiredOrientation; }; Timeslicer < Npc*, NpcJobInput, NpcJobOutput, kMaxNpcs, false, false > m_npcTimeslicer; }; void NpcManager::Init() { auto newBatchFunc = [this](Npc **aKey) unsigned { for (unsigned i = 0; i < m_numNpcs; ++i) { aKey[i] = GetNpc(i); } return m_numNpcs; }; auto setUpInputFunc = [this](Npc *pNpc, Input *pInput)->void { pInput->m_targetPos = GetTargetPosition(pNpc); } auto jobFunc = [this](Npc *pNpc, const Input &input, Output *pOutput)->void { pOutput->m_desiredOrientation = LookAt(pNpc, input.m_targetPosition); }; m_npcTimeslicer.Init ( newBatchFunc, setUpInputFunc, jobFunc ); } void NpcManager::UpdateFrame(float dt) { m_timeslicer.Update(maxJobsPerFrame); for (Npc &npc : m_npcs) { Output output; if (!m_timeSlicer.GetOutput(&npc, &output)) { npc.SetDesiredOrientation(output.m_desiredOrientation); } npc.Animate(dt); } }
|
下面是完整的timeslicer公用類別。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201
| template < typename Input, typename Output, typename Key, unsigned kMaxBatchSize, bool kSyncInput, bool kSyncOutput > class Timeslicer { private: struct JobParams { Key m_key; Input m_input; Output m_output; }; struct JobResults { Key m_key; Output m_output; }; unsigned m_batchSize; unsigned m_iJobBegin; unsigned m_iJobEnd; JobParams m_aJobParams[kMaxBatchSize]; static const unsigned kMaxHistorySize = kSyncOutput ? 2 * kMaxBatchSize : kMaxBatchSize; typedef RingBuffer<JobResults, kMaxHistorySize> History; History m_history; typedef std::function<unsigned (Key *)> NewBatchFunc; NewBatchFunc m_newBatchFunc; typedef std::function<void (Key, Input *)> SetUpInputFunc; SetUpInputFunc m_setUpInputFunc; typedef std::function<void (Key, const Input &, Output *)> JobFunc; JobFunc m_jobFunc; public: void Init ( NewBatchFunc newBatchFunc, SetUpInputFunc setUpInputFunc, JobFunc jobFunc ) { m_newBatchFunc = newBatchFunc; m_setUpInputFunc = setUpInputFunc; m_jobFunc = jobFunc; Reset(); } void Reset() { m_batchSize = 0; m_iJobBegin = 0; m_iJobEnd = 0; } bool GetOutput(Key key, Output *pOutput) const { for (const JobResults &results : m_history.Reverse()) { if (key == results.m_key) { *pOutput = results.m_output; return true; } } return false; } void Update(unsigned maxJobsPerUpdate) { TryStartNewBatch(); StartJobs(maxJobsPerUpdate); FinishJobs(); } private: void TryStartNewBatch() { if (m_iJobBegin == m_batchSize) { if (kSyncOutput) { for (unsigned i = 0; i < m_batchSize; ++i) { const JobParams ¶ms = m_aJobParams[i]; SaveResults(params); } } Reset(); Key aKey[kMaxBatchSize]; m_batchSize = m_newBatchFunc(aKey); for (unsigned i = 0; i < m_batchSize; ++i) { JobParams ¶ms = m_aJobParams[i]; params.m_key = aKey[i]; if (kSyncInput) { m_setUpInputFunc(params.m_key, ¶ms.m_input); } } } } void StartJobs(unsigned maxJobsPerUpdate) { unsigned numJobsStarted = 0; while (m_iJobEnd < m_batchSize && numJobsStarted < maxJobsPerUpdate) { JobParams ¶ms = m_aJobParams[m_iJobEnd]; if (!kSyncInput) { m_setUpInputFunc(params.m_key, ¶ms.m_input); } m_jobFunc ( params.m_key, params.m_input, ¶ms.m_output ); ++m_iJobEnd; ++numJobsStarted; } } void FinishJobs() { while (m_iJobBegin < m_iJobEnd) { const JobParams ¶ms = m_aJobParams[m_iJobBegin++]; if (!kSyncOutput) { SaveResults(params); } } } void SaveResults(const JobParams ¶ms) { JobResults results; results.m_key = params.m_key; results.m_output = params.m_output; if (m_history.IsFull()) { m_history.Dequeue(); } m_history.Enqueue(results); } };
|
執行緒
如果你的遊戲引擎支援多執行緒,我們可以進一步將工作分散到多個執行緒上。現在一件工作開始時,會建立一條執行緒來執行那一件被分割的程式邏輯,而一件工作的結束,則是等待該執行緒結束。我們需要使用讀寫鎖(read/write lock)來確保timeslicer正確的處理剩下的遊戲邏輯。下面的程式碼標示出了需要更改的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115
| class Timeslicer { RwLock m_lock; struct JobParams { std::thread m_thread; Key m_key; Input m_input; Output m_output; }; bool GetOutput(Key key, Output *pOutput) const { ReadAutoLock readLock(m_lock); for (const JobResults &results : m_history.Reverse()) { if (key == results.m_key) { *pOutput = results.m_output; return true; } } return false; } void TryStartNewBatch() { WriteAutoLock writeLock(m_lock); if (m_iJobBegin == m_batchSize) { if (kSyncOutput) { for (unsigned i = 0; i < m_batchSize; ++i) { const JobParams ¶ms = m_aJobParams[i]; SaveResults(params); } } Reset(); Key aKey[kMaxBatchSize]; m_batchSize = m_newBatchFunc(aKey); for (unsigned i = 0; i < m_batchSize; ++i) { JobParams ¶ms = m_aJobParams[i]; params.m_key = aKey[i]; if (kSyncInput) { m_setUpInputFunc(params.m_key, ¶ms.m_input); } } } } void StartJobs(unsigned maxJobsPerUpdate) { WriteAutoLock writeLock(m_lock); unsigned numJobsStarted = 0; while (m_iJobEnd < m_batchSize && numJobsStarted < maxJobsPerUpdate) { JobParams ¶ms = m_aJobParams[m_iJobEnd]; if (!kSyncInput) { m_setUpInputFunc(params.m_key, ¶ms.m_input); } params.m_thread = std::thread([¶ms]()->void { m_jobFunc ( params.m_key, params.m_input, ¶ms.m_output ); }); ++m_iJobEnd; ++numJobsStarted; } } void FinishJobs() { WriteAutoLock writeLock(m_lock); while (m_iJobBegin < m_iJobEnd) { JobParams ¶ms = m_aJobParams[m_iJobBegin++]; params.m_thread.join(); if (!kSyncOutput) { SaveResults(params); } } } };
|
如果你的遊戲可以再多承受一個影格的延遲,而且你不想要timeslicer佔據一個執行緒,那麼你可以稍微調整update函式。讓工作在當前影格更新結束之前開始,然後在下一個影格開始時結束。
1 2 3 4 5 6
| void TimeSlicer::Update(unsigned maxJobsPerUpdate) { FinishJobs(); TryStartNewBatch(); StartJobs(maxJobsPerUpdate); }
|
總結
就是這樣!我們看到了批次邏輯的時域切割是如何增進遊戲效能,以及四種不同輸入輸出時機的組合,每一種都有它們的用處(呃,或許最後一種沒有)。也看到了時域切割的邏輯怎麼進一步改寫來跟執行緒結合。
我希望你會覺得這有用。😊